
The Life of Popular Music

The purpose of music is multifaceted. The head-bobbing rhythms; the sing-along anthems (this is my jam); movie soundtrack theme songs. It is no surprise how impactful music is to the world. Some might even say that there is no life without music - I am one of such folks.
Given how expansive music is, in areas such as genre and number of songs available, when it comes to distinguishing ‘good’ music from ‘great’ music, the Billboard Hot 100 charts are considered the music industry standard for defining the most popular songs on any given year. Billboard has been releasing charts since the 1950s, and I, being the curious Data Scientist with a strong passion in music, yearns to know what made songs ‘click’ for society over the last sixty-plus years.
Using Billboard Hot 100 charts from 1950-2018 and Spotify’s API, I set out to discover what music trends and shifts exist for popular music over the past six decades.
Approach
For this initiative, I define ‘great’ or ‘popular’ music to be any song that was listed in the Billboard Hot 100 charts.
In terms of data collection, we can rely on two sources:
- For songs made between 1950 - 2015, I leverage data from GitHub user Kevin Schiach. The data contains interesting features such as song sentiment, Flesch-Kincaid metric (determines how complex and readable text or song lyrics are), number of difficult words, and more
- Songs made 2016 and onwards we can first manually pull artist and track names from Wikipedia with the Python library Pandas, specifically by using the ‘read_html’ function. Afterwards, we can capture the other features found in Kevin Schiach’s data (e.g. Flesch-Kincaid) with the help of other Python libraries such as vaderSentiment and textstat
In addition, we can utilize Spotify’s API (an endpoint called get audio features) to capture other song features like loudness, speechiness (how many spoken words are present in a track), tempo, valence (how much musical positiveness is present in a track), and more. Combining Spotify audio features with my initial set, that brings the song features’ total count to 37.
You can find more information on all features via Kevin Schiach’s repository here and Spotify for Developers page here.
Exploratory Data Analysis
With the song features, we can proceed to do some exploratory data analysis to see how exactly did popular music change in the past sixty years.
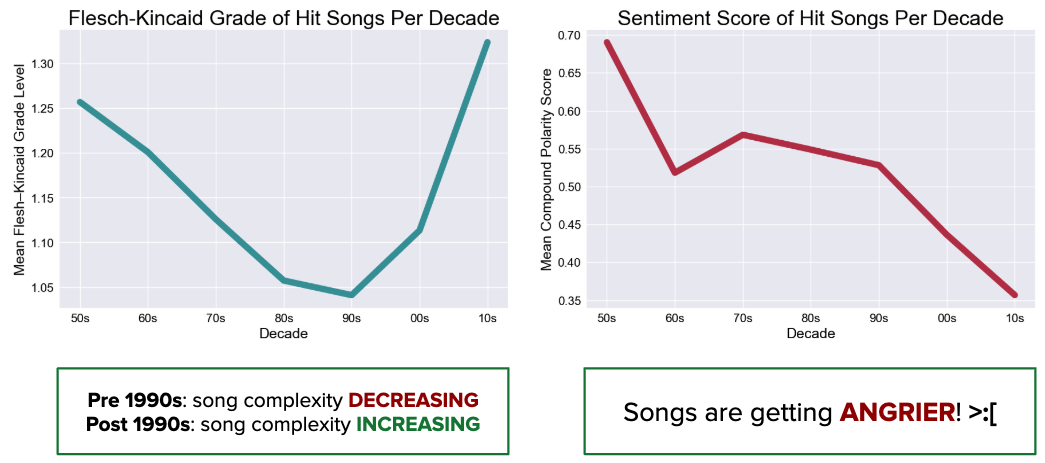
Above, we can see at a high-level how music has shifted over the last six decades through two specific features: the Flesch-Kincaid Grade Level and Sentiment Analysis Score.
The Flesch-Kincaid metric uses a variety of linguistics data like average sentence length, word length, and complexity (e.g. number of syllables) to calculate the readability of text. After applying the Flesch-Kincaid metric on song lyrics, we can see how between Billboard Hot 100’s inception to the 1990s, songs have gradually become less complex and easier to interpret. However, from the 90s onwards we see that popular music have become more complicated by the sharp positive slope at the end of the graph.
Sentiment Analysis is a natural language processing technique that quantifies how positive, negative, or neutral a piece of text is. The ‘compound score’ ranges on a scale of -1 to 1, where scores less than -0.05 represent negative sentiment texts, and scores greater than +0.05 represent positive sentiment texts. On the right, we see the sentiment analysis results, where it appears that songs have gotten less positive (angrier?) over the years.
Genre Representation
Next, we see how much each genre represented a decade’s Billboard Hot 100 charts.
To get here, I came up with 15 aggregate genres, and based on each track’s initial genre tags, I assigned each song to an aggregate genre with the help of cosine similarity calculations (see below for Python code walkthrough):
# Creating 15 aggregated genres
aggregate_genres = [{"rock": ["symphonic rock", "jazz-rock", "heartland rock", "rap rock", "garage rock", "folk-rock", "roots rock", "adult alternative pop rock", "rock roll", "punk rock", "arena rock", "pop-rock", "glam rock", "southern rock", "indie rock", "funk rock", "country rock", "piano rock", "art rock", "rockabilly", "acoustic rock", "progressive rock", "folk rock", "psychedelic rock", "rock & roll", "blues rock", "alternative rock", "rock and roll", "soft rock", "rock and indie", "hard rock", "pop/rock", "pop rock", "rock", "classic pop and rock", "psychedelic", "british psychedelia", "punk", "metal", "heavy metal"]},
{"alternative/indie": ["adult alternative pop rock", "alternative rock", "alternative metal", "alternative", "lo-fi indie", "indie", "indie folk", "indietronica", "indie pop", "indie rock", "rock and indie"]},
{"electronic/dance": ["dance and electronica", "electro house", "electronic", "electropop", "progressive house", "hip house", "house", "eurodance", "dancehall", "dance", "trap"]},
{"soul": ["psychedelic soul", "deep soul", "neo-soul", "neo soul", "southern soul", "smooth soul", "blue-eyed soul", "soul and reggae", "soul"]},
{"classical/soundtrack": ["classical", "orchestral", "film soundtrack", "composer"]},
{"pop": ["country-pop", "latin pop", "classical pop", "pop-metal", "orchestral pop", "instrumental pop", "indie pop", "sophisti-pop", "pop punk", "pop reggae", "britpop", "traditional pop", "power pop", "sunshine pop", "baroque pop", "synthpop", "art pop", "teen pop", "psychedelic pop", "folk pop", "country pop", "pop rap", "pop soul", "pop and chart", "dance-pop", "pop", "top 40"]},
{"hip-hop/rnb": ["conscious hip hop", "east coast hip hop", "hardcore hip hop", "west coast hip hop", "hiphop", "southern hip hop", "hip-hop", "hip hop", "hip hop rnb and dance hall", "contemporary r b", "gangsta rap", "rapper", "rap", "rhythm and blues", "contemporary rnb", "contemporary r&b", "rnb", "rhythm & blues","r&b", "blues"]},
{"disco": ["disco"]},
{"swing": ["swing"]},
{"folk": ["contemporary folk", "folk"]},
{"country": ["country rock", "country-pop", "country pop", "contemporary country", "country"]},
{"jazz": ["vocal jazz", "jazz", "jazz-rock"]},
{"religious": ["christian", "christmas music", "gospel"]},
{"blues": ["delta blues", "rock blues", "urban blues", "electric blues", "acoustic blues", "soul blues", "country blues", "jump blues", "classic rock. blues rock", "jazz and blues", "piano blues", "british blues", "british rhythm & blues", "rhythm and blues", "blues", "blues rock", "rhythm & blues"]},
{"reggae": ["reggae fusion", "roots reggae", "reggaeton", "pop reggae", "reggae", "soul and reggae"]}]
# helper function to calculate cosine similarities between each track's genre tags and tags associated with each of the 15 aggregate genre
import math
from collections import Counter
def counter_cosine_similarity(c1, c2):
terms = set(c1).union(c2)
dotprod = sum(c1.get(k, 0) * c2.get(k, 0) for k in terms)
magA = math.sqrt(sum(c1.get(k, 0)**2 for k in terms))
magB = math.sqrt(sum(c2.get(k, 0)**2 for k in terms))
return dotprod / (magA * magB)
# create a series that assigns an 'aggregated genre' to each song track
list_of_genres = []
# iterate through each track
for track_tags in df_final_set['tags']:
sim_counter = 0
final_genre = 'N/A'
if type(track_tags) is not float:
if (len(track_tags) != 0):
# iterate through each aggregated genre
for genre in aggregate_genres:
# pull genres associated with each aggregated genre
for agg_genre, genres in genre.items():
# calculate cosine similarity between track tags vs. genres associated with aggregated genre
sim_temp = counter_cosine_similarity(Counter(track_tags), Counter(genres))
# if cosine similarity value is greater than counter, then update
if sim_counter < sim_temp:
sim_counter = sim_temp
final_genre = agg_genre
# add aggregated genre to list
list_of_genres.append(final_genre)
# create column 'agg_genre' in DataFrame
df_final_set['agg_genre'] = pd.Series(list_of_genres,index=df_final_set.index)
The main takeaway from this analysis is how the genre ‘Rock’ was the Billboard Hot 100 charts’ majority-genre from inception the 80’s. It wasn’t until the 90’s that we see the uprising of other genres such as Pop, Hip-Hop / R&B, and Electronic / Dance.
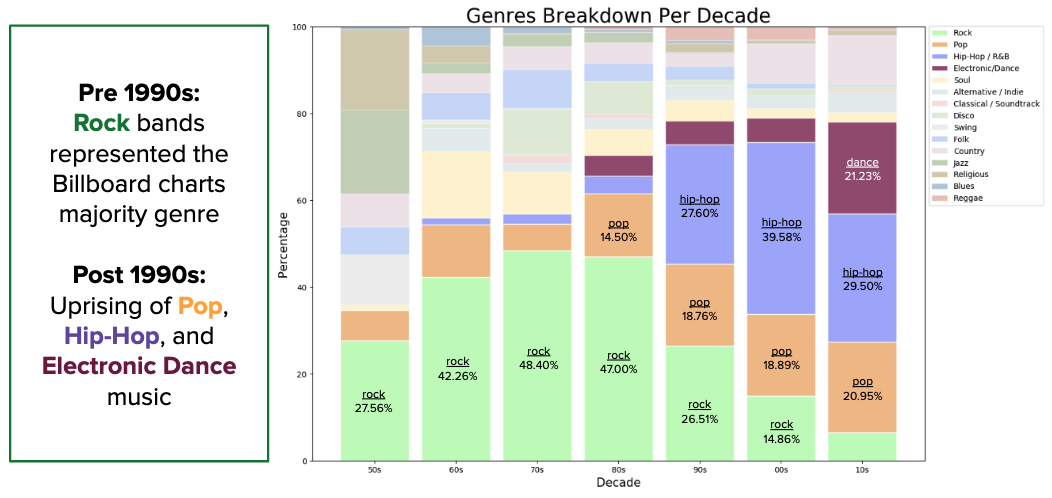
The Rise of Hip-Hop and R&B
Looking at other song features related to song lyrics or words themselves (e.g. number of difficult words), we see on average that the genre Hip-Hop / R&B has the greatest amount of these qualities relative to other genres. This analysis, along with the fact that hip-hop rose in popularity since the 90’s, explains why we saw the increase in the Flesch-Kincaid metric previously.
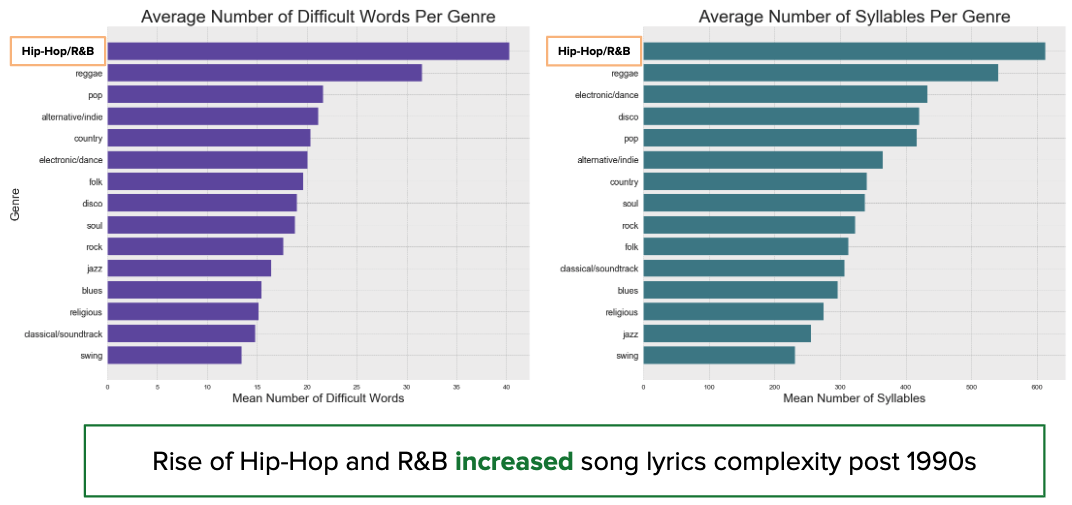
Other Trends
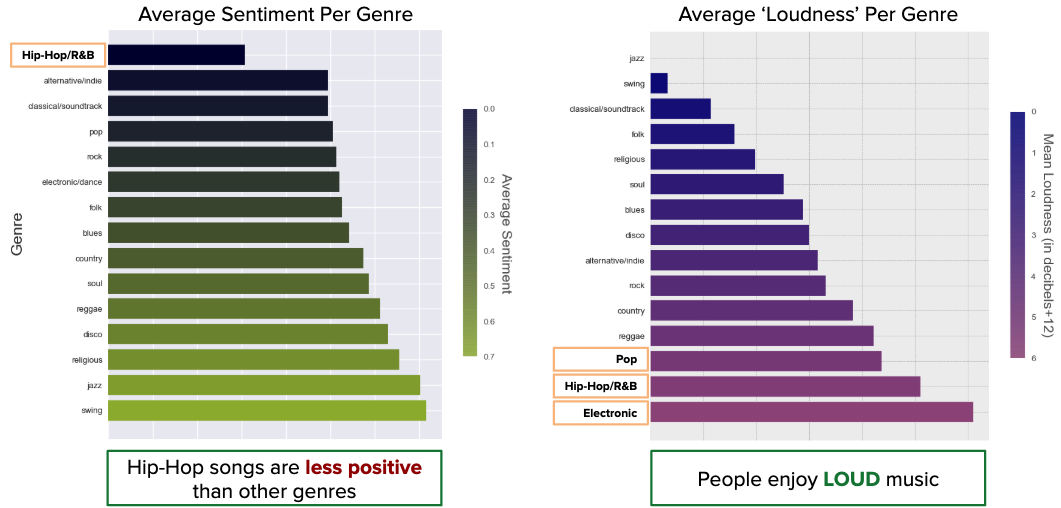
Going back to the sentiment analysis results, but now at the genre-level, what we can see is that Hip-Hop / R&B is less positive relative to other genres. Given this, and the previously mentioned fact that hip-hop rose to fame in the 90’s, we can see why popular songs have become increasingly negative over time.
In addition, when referring to the Spotify audio feature ‘Loudness’, notice how the top three genres of today - Pop, Hip-Hop, and Electronic - are the loudest relative to other genres. What we can learn from this visual is that people today tend to gravitate towards loud music. Unfortunately, not often does one see the ‘quieter’ genres, like Jazz and Blues, get represented in the Billboard Hot 100. That doesn’t mean they’re not good though! (if you’re willing, and have a premium Spotify account, check this album out - it’s wild.)
Consistent Song Topics
Another useful tool for text analysis is a WordCloud - which is a space filled with words in different sizes, where the word sizes represent the frequency or importance of each word. In other words, the larger the font size of a word in a WordCloud, the greater that word’s importance.
Below we have two WordClouds - one for pre-1990’s, one for post-1990’s.

Despite the pivot in the nineties, where songs lyrics became increasingly complex and angry, what we see from these WordClouds is that song topics generally stayed the same.
wIn essence, to write a popular hit song, all you need is love. And possibly a baby girl to know (?!)
In Summary…
Overall, per the data analysis, main takeaways are as follows:
- The nineties was a pivotal decade for music, where we saw a shift in music genre taste, from Rock to Hip-Hop / R&B, Pop, and Electronic / Dance
- Due to the rise in popularity for genres such as Hip-Hop, with songs that are very lyrically-driven, we see the shift in popular music features post the ninties, where:
- Songs became more complex and wordy
- Songs are louder
- Songs are less positive
Content-Based Recommendation Flask App
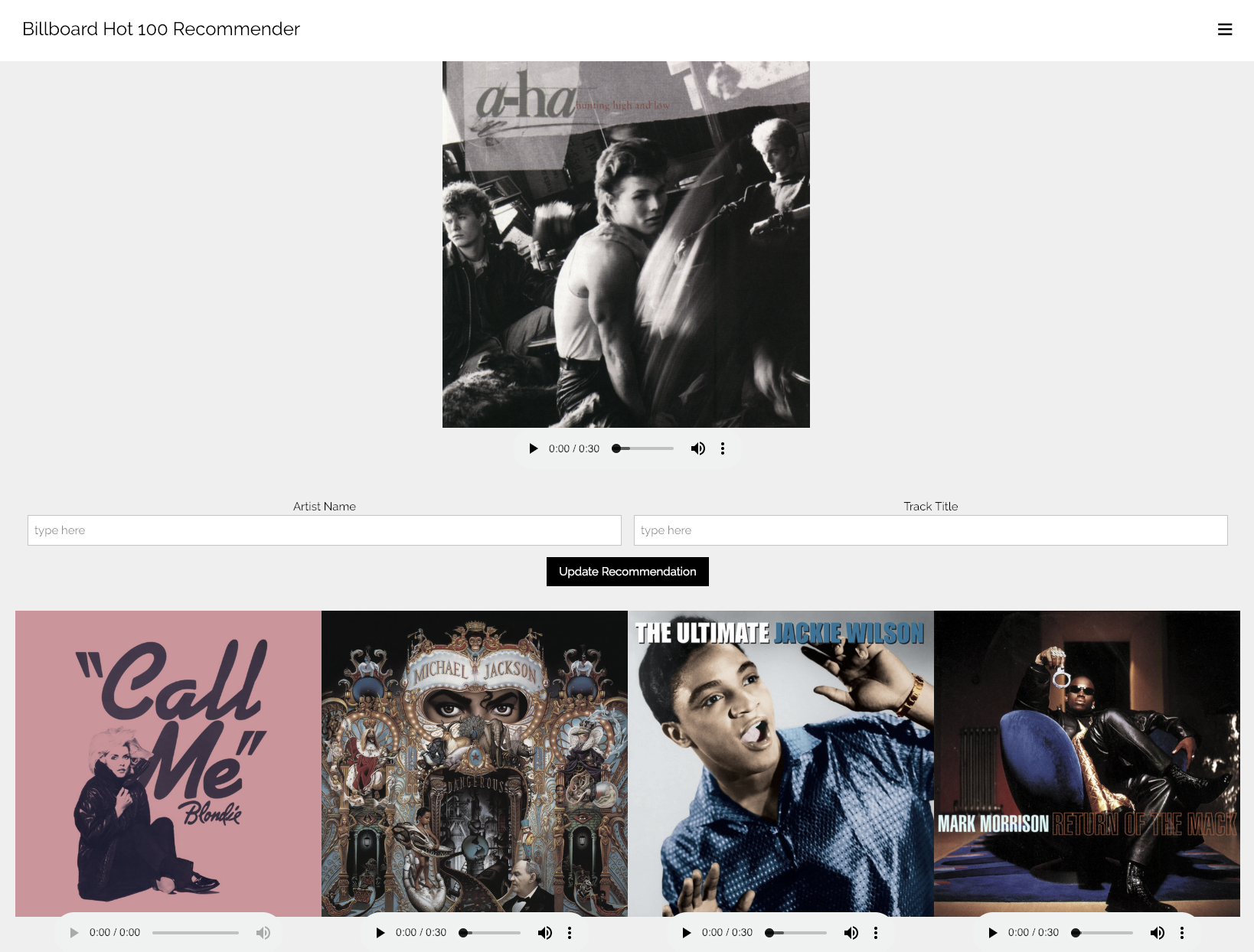
For fun, I decided to create a music recommendation Flask app based on my dataset of popular songs. The web application basically allows an end-user to search for a Billboard Hot 100 song, provides statistics on searched song (e.g. sentiment score), and recommends four other Billboard Hot 100 songs, from any year, that are similar to the searched song.
The content-based recommendation app was built using NLP techniques such as lemmatization and Word2Vec to process both song lyrics and every track’s associated audio features, along with the unsupervised learning algorithm Nearest Neighbor in order to calculate the cosine similarities between different song feature vectors.
With the help of the Spotify API, additional features in the Flask app include displaying album covers of searched/recommended songs and providing track samples for the end-user to listen to (if available via Spotify.)
Click image to check out a video of my Flask App in action!
Additional Details
If you want to see the nitty-gritty details of how I went about creating the data visuals or Flask app shown in this post, here’s the link to my GitHub repository for this project.
Thanks for reading! :)